How to Get Into SRE
I’ve been giving talks and ranting in tweets for several years now, and the same question crops up again and again: “How do I get into SRE? How do I get there from here?”
My answer is usually rambling and long. So long, that sometimes I don’t even write back. There is simply too much to say! Too much history. Too much context. Too many factors for each person’s individual situation.
So, here it is. My formal ramblings on how to get into SRE: what I think it is, how I got there, how you can get there, and how to do it. This post is a guide and meant for bookmarking, referencing, and sharing. It provides insights that you can map to your specific situation to get you started on your specific path.
I hope you find this useful in your journey.
Table of Contents
Definition
So, what is Site Reliability Engineering? According to Ye Ole Google SRE book: “SRE is what happens when you ask a software engineer to design an operations team.” This definition is a bit contested for multiple reasons, not least of which being it implies operations teams are incapable of sound systems design rather than being permanently under-resourced. It’s also contested because it implies all SREs are coding backend systems day-in and day-out, and that’s not even true at Google.
And while Google has thrown quite a bit of money into selling their definition of SRE, the rest of the industry has adopted SRE on its own terms, with results ranging widely from company to company. In my time with the title, I’ve seen SRE refer to:
- The team that owns incident response
- The team that owns internal deployment tooling
- The team that owns the data center
- The team that owns reliability processes for all of engineering
- The team that owns the container platform
- The team that owns the databases
- The team that owns the network
- The team that owns monitoring
- The team that is embedded onto dev teams to own all the things devs don’t want to own
I want to be clear: this guide isn’t about Google SRE. Google SRE is its own flavor of SRE practices and in some ways a completely different discipline. Other large companies may adopt pieces of Google SRE, but I don’t know of anywhere other than Google that practices it fully. If you want to be a Google SRE, that’s perfectly fine. But this post isn’t for that.
So what, then, is the broader definition of SRE? It’s difficult to nail down one definition for all companies in the same way it’s difficult to define Software Engineering for all companies. If Software Engineers are defined by code, then SREs are also SEs. What then, is the difference between an SRE and an SE who is on-call?
If you twist my arm, I would define Site Reliability Engineering as: “the practice of building and maintaining a reliable SaaS platform at scale.” I see SRE as something for companies with large SaaS offerings, usually a high-traffic website and associated services. That is, I take the “Site Reliability” part pretty literally.
(You could argue the need for SREs on large internal services, such as a database, but I would argue in return that such a service is probably supporting a larger customer-facing platform :) ).
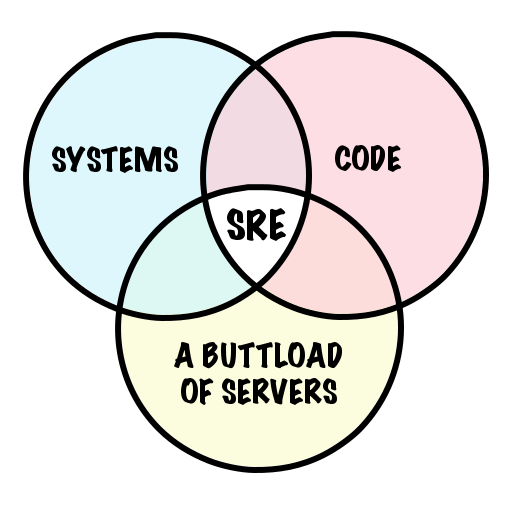
A Software Engineer who is on-call understands how their code works, how it can break, and how to fix it. A Site Reliability Engineer understands how that code fits into the larger tapestry of the company’s architecture and tries to set the whole system up for success.
Given this definition, what are some key skill areas for an SRE?
- Software engineering
- Distributed systems design
- Operating systems
- Networking
- Databases
- Security
- Reliability best practices
- Troubleshooting
- Customer support
“That’s a lot!” It is. SRE is a broad discipline, because it takes a lot of skill to run a large, distributed site. In fact, many SREs tend to specialize in one or two of these skills. You’ll find companies often have multiple SRE teams focused on different areas of running its platform. You’ll find teams doing SRE but under a different name, such as Infrastructure Engineering or Production Engineering. You’ll also find companies with SRE teams that aren’t doing SRE work at all. I would encourage you to focus on the work itself and not get too tied up in the actual title. You can put anything on LinkedIn.
Realities
Whenever people ask me how to get into SRE, they usually leave off why they want to go there. It seems rude to ask in the moment, but let’s use this time to address some possible misconceptions about the field. Due to the deep marketing of Google’s model vs the broader industry adaptation, there can be a wide difference between Expectation and Reality.
Expectation
- You get a leather jacket
- You’re paid more than the devs
- Everyone listens to what you say
- You have authority over shipping deadlines and bug priorities
- You’re always working on Bleeding Edge World-Spanning Tech
- You hardly ever do manual work, just code all the time
- You can give up your pager if the on-call is rough
Reality
- You are paid the same as the devs
- Sometimes less, if you consider on-call burden
- You’re on-call for your own stuff
- Sometimes the devs’ stuff, too!
- You can go months at a time without coding
- At the same time, you will be expected to know how to read and diagnose code issues
- You may be in charge of reliability, but have no authority to fix it
- You will need developed customer support skills to convince developers to adopt best practices for running at scale
These Realities aren’t true everywhere, but they are more true than the Expectations. Some days you’re building tooling for your new fancy platform and other days you’re fighting with Puppet and DNS. You will need to be flexible and build up a wide range of skills to do your job.
Some Other Realities of SRE
- Troubleshooting really interesting problems that can’t be solved with StackOverflow
- Opportunity to learn a variety of disciplines across the entire software / hardware stack
- Experiencing the thrill of at-scale problems, from deploying across thousands of servers to mitigating DDoS attacks
- Advancing processes completely new to your company
- Honing your communication skills, from internal development process disputes to long and very public incident post-mortems
- The trust that comes with being someone who owns and maintains production platforms
- Working with engineering professionals at the top of their fields and careers
This is all a very long-winded way of saying: if you are in it for the power and glory, you will likely be disappointed. Become an SRE because the work interests you.
My Path
Sometimes people grill me on the specific steps I took in my career: book titles, companies, conferences, etc. They want as much information as possible so they can try to replicate my path. The problem is, my path isn’t easy to replicate.
My general path
- Grew up around computers and spotty internet aka lots of time to poke around when bored
- Got a film degree
- Graduated during a recession and couldn’t get a job in a creative field
- Took a tech support job to pay my student loans
- Become fascinated by server admin duties
- Got turned into a glorified receptionist/sales rep instead
- Grew bored and started learning Python at night
- Left for better support job at different company
- Befriended cool developers, kept learning Python at night
- Interviewed for Python job
- Didn’t get it
- Interviewed for internal tools job
- Got it
- Ops teammate went on paternity leave and I temporarily took over his duties
- SRE manager asked me to join the SRE team
If you step back, mine is a cool story of a film student who became a tech worker. Just work hard enough, and you too shall realize your dreams! But there are parts of that path other people can’t copy. For example, when I interviewed for my support roles I was a young, white, feminine-presenting woman being hired by older, white men with families. They decided to “take a chance on me” and said I reminded them of their daughters. One man even based my interview around his younger daughter’s school homework! This association didn’t feel great, but it did work to my advantage, and I can’t help you replicate it.
One part of my path that I think you can and should replicate is constant learning. My entire tech career has been one of two jobs: the job I have and the job I’m learning. I am constantly reading books, watching talks, taking classes, learning new languages, and talking to industry friends. I don’t rest on my laurels. If I’m not interested in what I’m currently working on during the day, I find something interesting at night and I do that. Eventually those new skills help me either in my current job or in securing the next one.
Something else I think you should do, that I did not do, is leverage your community. I had no idea the tech community was a thing until I started working at a tech company. I was banging my head against Python problems all alone instead of attending meetups and getting help. I went into the job hunt cold, without knowing anyone or anything about what I was doing. I landed on my feet, but I think that says more about the economy, my privilege, and pure luck than it does my abilities. Leverage your community! It will help you get a job.
Your Path
I meet people from all different backgrounds who want to get into SRE. Some people are already developers, some are in bootcamps, some are in QA or marketing, and they all want to know what their next steps should be.
The official answer is “it depends,” which is the answer for everything when considered at the right depth! But I know that’s not helpful or actionable, so let’s slice it a different way.
If I was trying to get into SRE right now, I would do two things:
- Locate the nearest SRE org to me (remember, it might not be called “SRE”!).
- Figure out how many hops it takes to get there.
You might not be familiar with the term “hops.” It’s a networking concept that refers to the number of routing networking devices (routers, bridges, etc) a packet hits between its source and its destination. It’s likely that a packet traveling between your laptop and your friend’s laptop on your home wifi will have less hops than a packet traveling between your laptop and a friend’s laptop in another country. Similarly, I would expect less hops between a developer who works with an SRE team at their company than someone studying film who wants to be an SRE after they graduate.
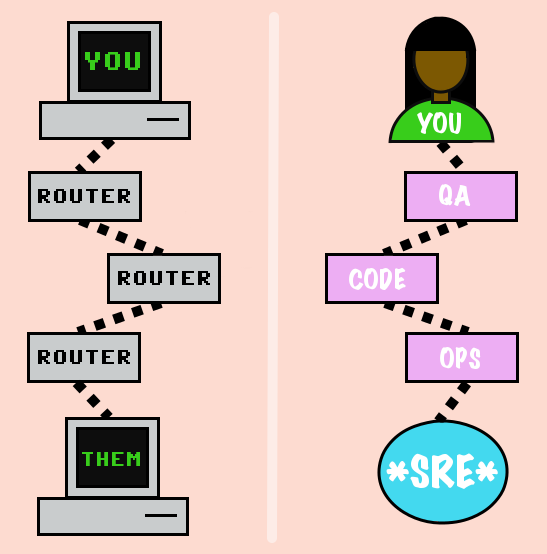
Hops in your career are “traveled” through a combination of skills and networking (people networking!). It’s a constant conversation of finding out what skills you need to make the next hop and finding people who will help you make it. It’s likely your next hop won’t be an SRE job, but it will get you closer!
Much like computer networking, the larger your social network, the more efficient your path will be. Depending on who helps you, the skills you have, and your timing, your path could be longer or shorter than someone else in your same place. One person’s path might look like bootcamp > freelance > part-time developer gig > ops work on the side > sysadmin job > operations job > SRE. Another person might find an internship on an SRE team fresh out of school. Different people have different opportunities, unfortunately. You need to be practical about yours.
So, figure out which SRE-related skills you need to acquire. Narrow it down to skills that, if you had them, you could get a new job that is closer to SRE. Acquire those skills. Get that job. Rinse. Repeat.
For example, if you don’t know how to program: learn to program! Go to a bootcamp, take online classes, get a CS degree, whatever works best for you. Expand your network and find people hiring. Or do freelance work. Get development work on your resume. Then use your new position in the industry to learn the next skill, like networking or databases. Take more classes, find more meetups, do more hackathons, find more jobs, get hired, get closer to SRE.
The hardest part is getting your foot in the door. Once you have a developer or sysadmin job, once you can put some form of “engineer” on your resume, you have room to breathe. Stay in that job for 1-2 years, get experience for your resume, build your network, and make your next pivot. It takes time, but this is likely the approach you will use for the rest of your career, to SRE and beyond.
Interviews
No matter how you get there, eventually you’ll be interviewing for an SRE job. Congrats! SRE interviews vary between companies and teams, depending on your duties. So, study the job posting ahead of time (you should be doing this anyway) and have examples ready for the main topics it covers.
In addition to the usual behavioral questions you get in all interviews, SRE interviews tend to cover coding, troubleshooting, and reliability.
Coding
- You will have to code, whether it’s a take-home scripting problem or a whiteboarding interview on-site.
- Usually they will tell you what languages are acceptable. If they don’t, ask.
- Typically any object-oriented language will do (Python, Ruby, C++, Java, etc) with a special exception for Go.
- I’ve seen advice to narrate everything you’re thinking, but that’s worked against me before. Take time to consider your approach in silence, then explain what you’re going to do. Repeat as needed.
- If it’s a take-home assignment without an explicit timer watching you, take all the time you have and need! Many coding assignments aren’t timed by employees before being placed in front of candidates, so you might need more time than they think you do.
- If they ask how long it took you, give a reasonable lie. Unless it’s in some proprietary app of theirs, they can’t tell.
Troubleshooting
- They will want to see how you think on your feet and how well you understand systems.
- This may take the form of experience examples, i.e. “Tell me about an outage you were part of and what you contributed.”
- It may also take the form of puzzles, i.e. “Developers in Timezone A complain about slow network connections every day at 3pm. How would you investigate this?”
- Feel free to ask questions (“Do I have root?”) and throw examples at the wall (“I would look at logs first, just in case the developers didn’t think to look there.”)
- The point of these questions is to see how well you know the systems you’ve worked with before, what sort of experiences you’ve had, and edge cases you’ve seen. The point is to judge depth, not correctness. Feel free to say, “That’s all I know about that” or “I don’t know, but I would try X.”
Reliability
- Reliability should be evident throughout your work.
- When you write code, you should be writing exception handling and tests as well. If you run out of time, write down or explain how you would go about this.
- What would you test? How? How would you roll out your changes? How would you roll them back?
- When you are troubleshooting, consider reliability and the risks you are taking with every step.
- Did you just suggest rebooting a server that’s still serving production traffic? How would you ensure that outage doesn’t happen again?
For an entry-level SRE, I would expect competency in one flexible programming language, like Python. You can make a small app, write tests, and handle exceptions. I would also want to see some competency in an operating system like Linux. You can navigate a filesystem on the command line, know how to grep logs, can ping a domain. And I would like to see some forethought of these skills at scale, such as playing around with config management systems or CI tools. You might not be able to afford to run AWS instances, but maybe you’ve played with a free Heroku account and checked out your app metrics in free monitoring add-ons. Wherever you go in your SRE career, be it Kubernetes or MySQL or edge networking, these foundational skills will set you up for success.
Now the fun part. There should be time left at the end of each interview for you to ask questions; that is, you get to interview the company. You should plan out these questions ahead of time and have them written down for reference. Note their answers, too. You want to get a sense of their work culture, projects, and general team health.
You might not get your dream job the first time. But asking some of these questions can help you understand how this job will set you up for your next job hunt.
“What projects have you worked on in the past six months?”
- SRE work is cyclical and a mixture of proactive and reactive. Six months should cover two quarters and give you a good idea of what your work balance will be.
- Did they code anything in that time? Or did they decommission 1,000 servers by hand? If they built something, did they write docs?
“When was the last time you were paged and what was it for?”
- Pages happen. We are on-call because we expect to be paged at some point.
- But there’s a difference between, “A major database failure happened and it was all-hands on deck” and “This old server stopped pinging and that’s where everything important lives and no one ever gets time to fix it.”
“Are all your dev teams on-call?”
- Distributing the on-call load is a key part of DevOps culture, and you should know what stage the company is at.
- Are all dev teams on-call? Are they transitioning there? If so, how long has it been? What teams still haven’t gone on-call? Take this questioning as far as you feel comfortable. You want to get a feel for the relationship between dev teams and the team you want to be on.
- You might also want to ask what you’ll be on-call for, if you don’t feel the subject has been exhausted. The answer to this might seem obvious, but you might also learn you’ll be on-call for the old Nagios installation that another team still hasn’t replaced.
You don’t ask these questions to ensure you end up at the best possible company. You ask these questions so you know what you’re agreeing to. For example, if you like your future teammates and benefits package, but you know you’re walking into a horrible on-call rotation, you can use that in your salary negotiations. Again, you will likely not end up in your dream job on the first try. All companies have their pros and cons. Go into your job hunt with a firm idea of what your deal-breakers are, and do your best to learn if a company has them.
Resources
So, you have an idea of what SRE is and you have a general path for getting there. The next step is developing your skills!
As discussed, there are many paths to SRE, including CS degrees and coding bootcamps. But those cost money and may be out of reach for you. I used free resources to get my foot in the door, and I think everyone should have that same opportunity.
Here is a collection of free educational resources provided by the SRE/Ops/Systems community. I haven’t personally used everything here, so they aren’t ranked. But they all come highly recommended. I included the type of material to make it easier for you to choose based on your learning style.
Don’t get hung up on learning everything here. Choose what looks interesting and choose something else if it doesn’t work out. Use this list as a study guide, a cheatsheet for filling gaps, or a way to see if you even enjoy SRE work at all!
Best of luck in your future career.
General / Multiple topics
- Ops School (docs collection)
- SRE Weekly (newsletter)
- SREcon (conference videos)
- DevOpsDays (conference videos)
- Eli the Computer Guy (videos)
- Katacoda (interactive training)
- Sysadmin Casts (podcast)
- The Google SRE Book (book)
- The Geek stuff (blog)
- DevOps BootCamp (course)
- Coursera (courses)
Architecture
Cloud
Databases
- sqlzoo (interactive SQL training)
- Andy Pavlo’s courses (online course material)
- Readings in Database Systems (book)
- Intro to SQL: Querying and managing data (online course with videos)
- MongoDB University (courses)
Git
- Introduction to git (video)
- Ry’s Git Tutorial (book)
- Learn git branching (interactive tutorial)
- Git Immersion (interactive tutorial)
Networking
- How DNS Works (comic)
- Understanding IP Addressing: Everything You Ever Wanted To Know (whitepaper)
- Beej’s Guide to Network Programming (book)
Operating system internals
- Operating system basics (video)
- Unix system calls p1 (video)
- Unix system calls p2 (video)
- fork() and exec() (video)
- Wizard Zines (online zines, mostly free)
- NAND2Tetris (online course / book)
- Programming from the Ground Up (book)
- MIT’S Operating System Engineering (course)
- Crash Course Computer Science (videos)
- Intro to Operating Systems (videos)
- Operating Systems: Three Easy Pieces (book)
Programming
- Codecademy (interactive tutorials)
- Learn Python (interactive tutorials)
- Awesome Python (curated list of resources)
- Automate the Boring Stuff (book)
- Learn to Program (book / tutorial)
- Higher-Order Perl (book)
Puppet
Security
- The Big Blog Post of Information Security Training Materials (blog)
- Cyber Aces (courses)
- Over the Wire (capture the flag games)
Unix / Linux operations
- The Unix Workbench (book)
- Advanced bash scripting guide (book)
- Introduction to Linux (online course)
- Unix toolbox (cheatsheet)
- Command Line Challenge (games)
